Hypernetworks
is all there is
Hypernetworks, or hypernets, are a type of neural network that generates the weights for another neural network called the target network. They offer several advantages in deep learning, including flexibility, adaptability, faster training, information sharing between tasks, and model size reduction. Hypernets have proven effective in various deep learning challenges, such as continual learning, where the model learns tasks sequentially without forgetting, zero-shot learning, where the model predicts classes not seen during training, and complex tasks in natural language processing (NLP) and reinforcement learning. While related to Progressive Neural Architecture (PEFT), hypernets and HyperDNNs tackle the challenges in a distinct manner.
Key Features of Hypernetworks
- Soft Weight Sharing- Hypernets excel in training to generate weights for multiple Deep Neural Networks (DNNs), particularly when tasks are interconnected. This differs from conventional weight sharing methods and enables the seamless transfer of information across related tasks.
- Dynamic Architectures- Hypernets have the capability to construct a neural network whose structure, such as the number of layers, can dynamically change during training or when making predictions. This proves beneficial in situations where uncertainty exists about the optimal network design in advance.
- Data-Adaptive DNNs- In contrast to standard DNNs with fixed weights post-training, HyperDNNs can adjust the primary network based on the input data. This adaptability enhances the model's responsiveness to varying input patterns.
- Uncertainty Quantification- Hypernets are adept at training networks that possess awareness of their prediction uncertainty. Achieved by creating multiple variations of the primary network, this feature is crucial for applications demanding precise predictions, such as those in the healthcare domain.
- Parameter Efficiency- HyperDNNs may necessitate fewer parameters compared to traditional DNNs, resulting in expedited training and potentially reduced computational requirements. This parameter efficiency contributes to a more resource-efficient and scalable deep learning model.
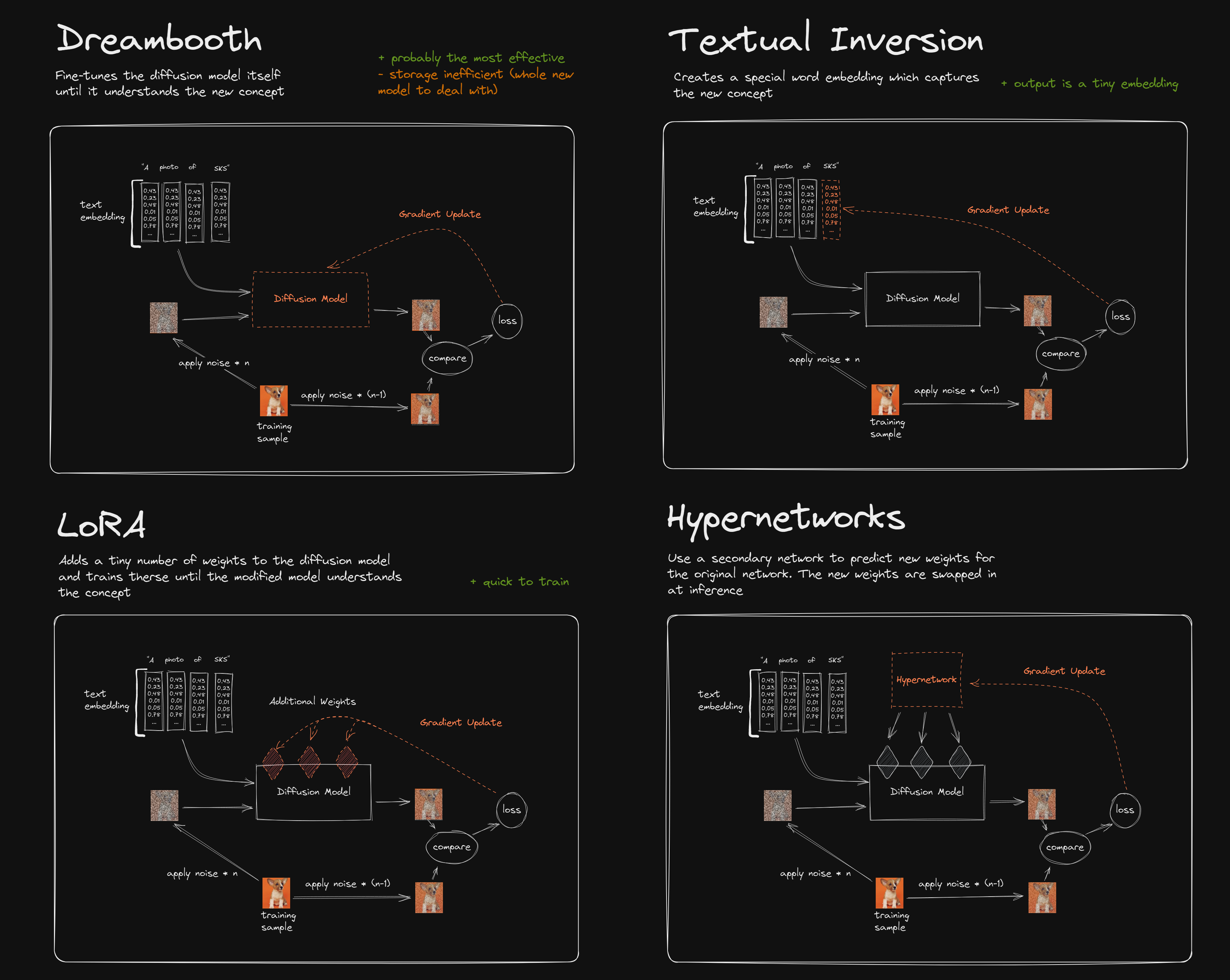
The image below, source, displays hypernetworks, LORA, Dreambooth and Textual Inversion in action for a diffusion model
Hypernetwork in Stable Diffusion Model
A hypernetwork can be a way of fine-tuning a Stable Diffusion model to change its style. A hypernetwork is a small neural network that is attached to a Stable Diffusion model. It affects the most important part of the model: the cross-attention module. This is the part that connects the input and the output of the model. LoRA models also change this part, but in a different way. A hypernetwork is usually a simple neural network that has a few layers, some dropout, and an activation function. It is similar to the basic neural networks. A hypernetwork modifies the cross-attention module by adding two networks that change the key and query vectors. These are the vectors that represent the input and the output of the model. We can see the difference between the original and the modified model in the diagrams below. When training a hypernetwork, the Stable Diffusion model is fixed, but the hypernetwork can learn from the data. Because the hypernetwork is small, it does not take a lot of time or resources to train it. You can train it on a normal computer. The main advantages of hypernetworks are that they are fast to train and have small file sizes. They can change the style of a Stable Diffusion model without changing the whole model. You should know that hypernetworks in Stable Diffusion are different from the hypernetworks that are usually used in machine learning. Those are networks that create the weights for another network. Hypernetworks in Stable Diffusion do not do that. They were not invented in 2016, but later. Source
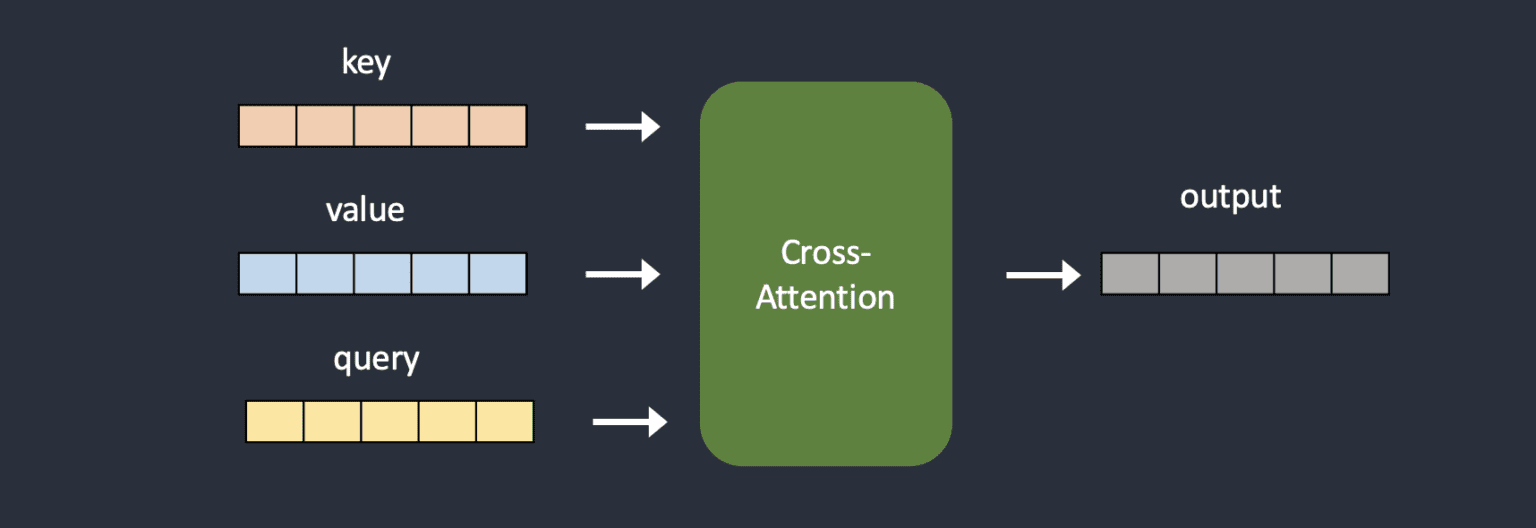
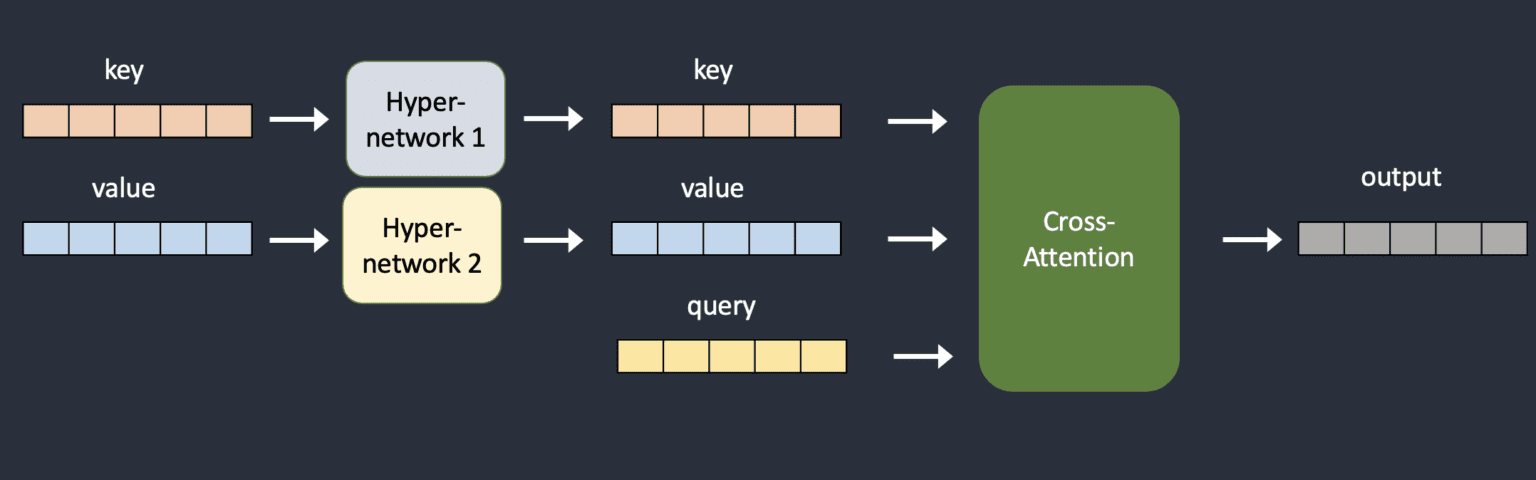
The cross-attention module of the original Stable Diffusion model and how hypernetwork injects additional neural networks to transform keys and values.
HyperDNN
- Hypernet Functionality: Hypernets generate weights for a primary or target network dynamically. This dynamic weight generation avoids the need to store a full set of weights for various tasks or conditions.
- HyperDNN Adaptability: HyperDNNs, composed of hypernets and their target networks, adapt to different tasks or conditions without a linear increase in parameters with the number of tasks. This adaptability enhances efficiency without a proportional growth in the model's complexity.
- Controller Role of Hypernetwork: A hypernetwork acts as a "controller" determining the behavior of another network by specifying its weights. The hypernetwork's role is akin to deciding the configuration of the target network.
- HyperDNN System Composition: HyperDNN refers to the entire system comprising a hypernetwork (generator of weights) and its associated target neural network (user of these weights). The HyperDNN, as a complete system, performs tasks with dynamically generated or modulated weights from the hypernet.
- Adaptive Behavior of HyperDNN: The behavior and performance of the HyperDNN are adaptive and flexible based on the conditioning or design of the hypernet. This adaptability allows the HyperDNN to respond dynamically to different inputs or learning conditions.
- Analogy of a Radio: The hypernetwork is analogous to a tuner dial in a radio, determining the frequency or station to tune into. The HyperDNN represents the entire radio system, incorporating both the tuner dial (hypernetwork) and the speaker (target network) producing sound for the chosen station.
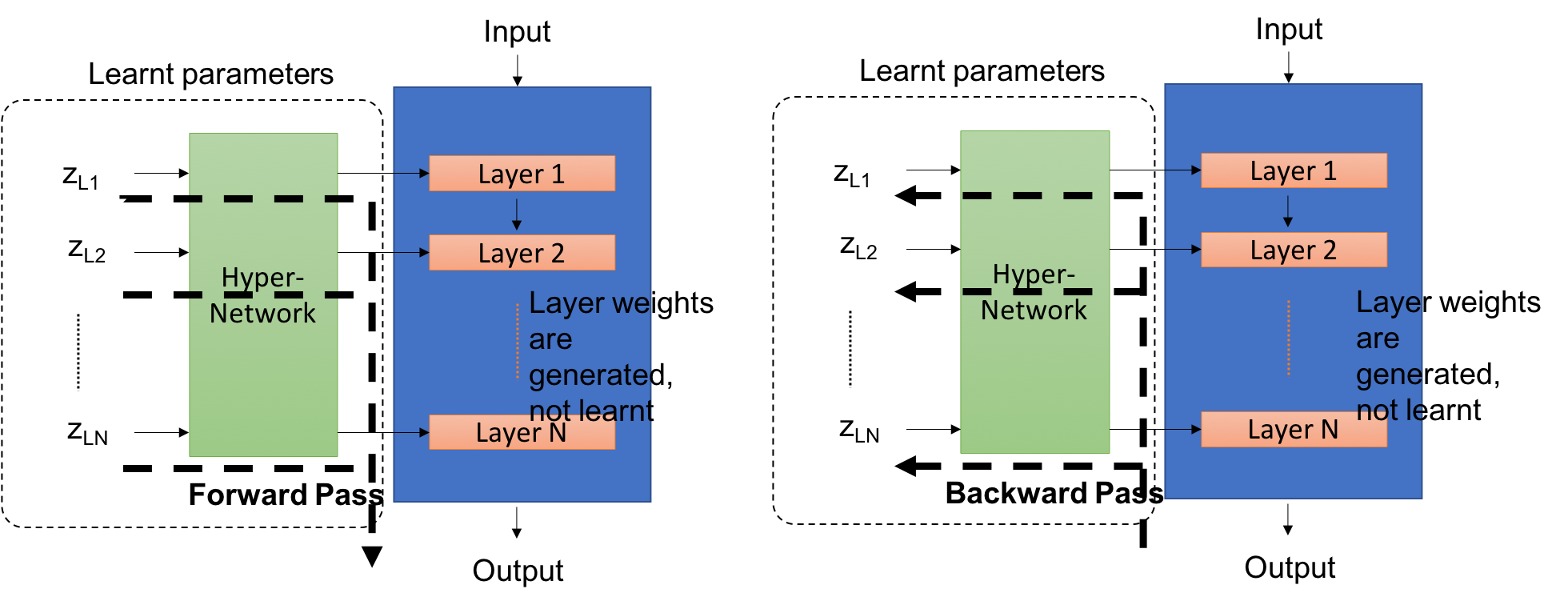
- Visualization in the Image: A standard DNN learns weights directly through gradient flows, while a HyperDNN utilizes a hypernet with weights to dynamically generate the DNN's weights during training. The image illustrates the distinction, emphasizing the dynamic weight generation process in a HyperDNN compared to the direct weight learning in a standard DNN.
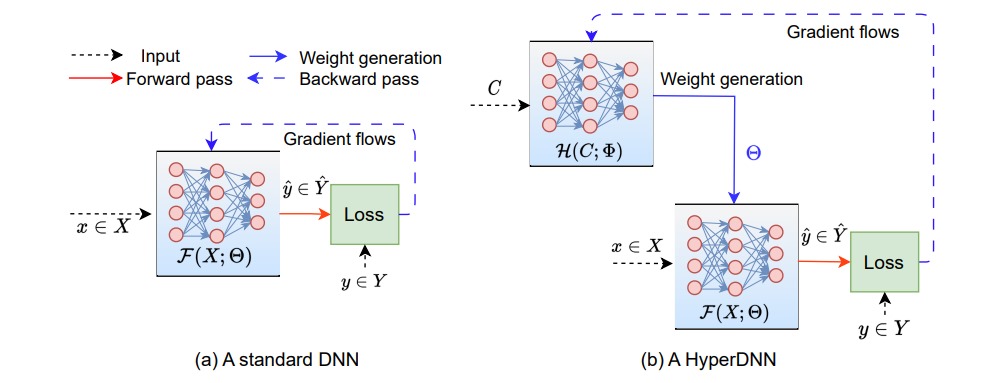
Difference between a standard DNN and a HyperDNN
HyperDNN Architecture (Four primary types based on their structural designs)
- MLPs (Multi-Layer Perceptrons): These use a fully connected structure where every input neuron connects to every output neuron, enabling extensive weight generation by utilizing the full input information.
- CNNs (Convolutional Neural Networks): These utilize convolutional layers to identify local and spatial patterns, making them ideal for tasks that involve spatial data like image or video analysis.
- RNNs (Recurrent Neural Networks): RNN hypernetworks contain recurrent connections, allowing them to process sequential information. This makes them apt for tasks like natural language processing or time series analysis.
- Attention-based Networks: These hypernetworks integrate attention mechanisms, enabling them to focus on relevant input features selectively. This helps in handling long-range dependencies and enhances the quality of the generated outputs.
Hypernets Pros and Cons
- Hypernets (Hypernetworks) Pros:
- Hypernetworks, present a range of advantages in the context of deep learning. One key strength lies in their flexibility and adaptability, derived from their unique ability to dynamically generate weights. This characteristic allows for the creation of models with designs that can swiftly adjust to evolving data patterns or changing task requirements. The soft weight-sharing capability of Hypernets is another significant advantage. By conditioning Hypernets to generate weights for multiple related Deep Neural Networks (DNNs), these systems facilitate effective information sharing between tasks, thereby promoting transfer learning and enhancing overall model performance. Additionally, the capability of Hypernets to generate weights for networks with dynamic architectures proves valuable in scenarios where the optimal network structure may be uncertain or undergo changes during training or inference. Moreover, the data-adaptive nature of HyperDNNs, which enables them to adjust to input data, adds to their versatility. Lastly, Hypernets excel in uncertainty quantification, as they can produce an ensemble of models with different sets of weights, aiding in the estimation of model uncertainty.
- Hypernets (Hypernetworks) Cons:
- Despite their strengths, the integration of Hypernets introduces certain challenges to the deep learning landscape. One significant drawback is the increased complexity in model design. The addition of a network tasked with generating weights for another network adds an additional layer of intricacy, potentially making the model more challenging to manage and comprehend. Training stability is another concern, given the indirect nature of weight generation in Hypernets, which may pose challenges in achieving stable and efficient training processes. Despite the potential for weight compression, the use of Hypernets may result in higher computational requirements, rendering them resource-intensive. Furthermore, the added layer of abstraction in Hypernets can make the model harder to interpret, presenting challenges for researchers and practitioners in understanding the underlying mechanisms and decision-making processes of the model.
HyperDNNs Pros and Cons
- HyperDNNs Pros:
- HyperDNNs, or Hyper Deep Neural Networks, offer several advantages within the realm of deep learning. Notably, they excel in parameter efficiency, capable of achieving weight compression, which may result in a reduced number of parameters compared to standard DNNs. The adaptability of HyperDNNs is a key strength, as their dynamically generated weights allow for better adjustment to varying input data or tasks. This adaptability, in turn, contributes to the potential for better performance on specific tasks when compared to traditional DNNs. Moreover, HyperDNNs showcase versatility across a wide spectrum of deep learning challenges, ranging from ensemble learning to neural architecture search.
- HyperDNNs Cons:
- One notable concern is the complexity associated with the indirect weight generation process, potentially making the training process more intricate and challenging. Another consideration is the risk of overfitting due to the added complexity and adaptability of HyperDNNs, necessitating careful management during the training phase. Furthermore, the dynamically generated weights may introduce performance variability across different inputs or conditions, posing a challenge in achieving consistent results. Lastly, despite the potential reduction in the number of weights, the computational cost of dynamically generating these weights can be resource-intensive, requiring careful consideration of computational resources during implementation.
References
A Brief Review of Hypernetworks in Deep Learning

